A web scraping script built with Python, BeautifulSoup, and Requests to extract detailed product information from Amazon product pages and save it into a CSV file for analysis.
This project is a web scraping script built with Python, BeautifulSoup, and Requests to extract detailed product information from Amazon product pages. The goal is to automate product data collection (title, price, ratings, reviews, description, and features) and save it into a CSV file for further analysis.
This scraper can be used by shoppers, data analysts, or businesses to:
A User-Agent header is added to mimic a browser and avoid being blocked.
The script checks the HTTP status code and handles cases like 403 (Blocked) or 503 (Server unavailable) gracefully.
Extracts multiple product details such as:
If an element is not found, the script prints a warning with debugging tips (e.g., "Inspect the HTML manually").
Extracted product details are written into a CSV file (amazon_airpod_pro_max.csv) for structured storage.
Columns include:
For the Apple AirPods Pro Max product page, the script extracts:
This project demonstrates real-world data collection & automation skills that can be applied in:
It's a solid foundation for data-driven decision-making in retail and marketing.
View a project demonstration and images of the outputs (click on the images to enlarge them)
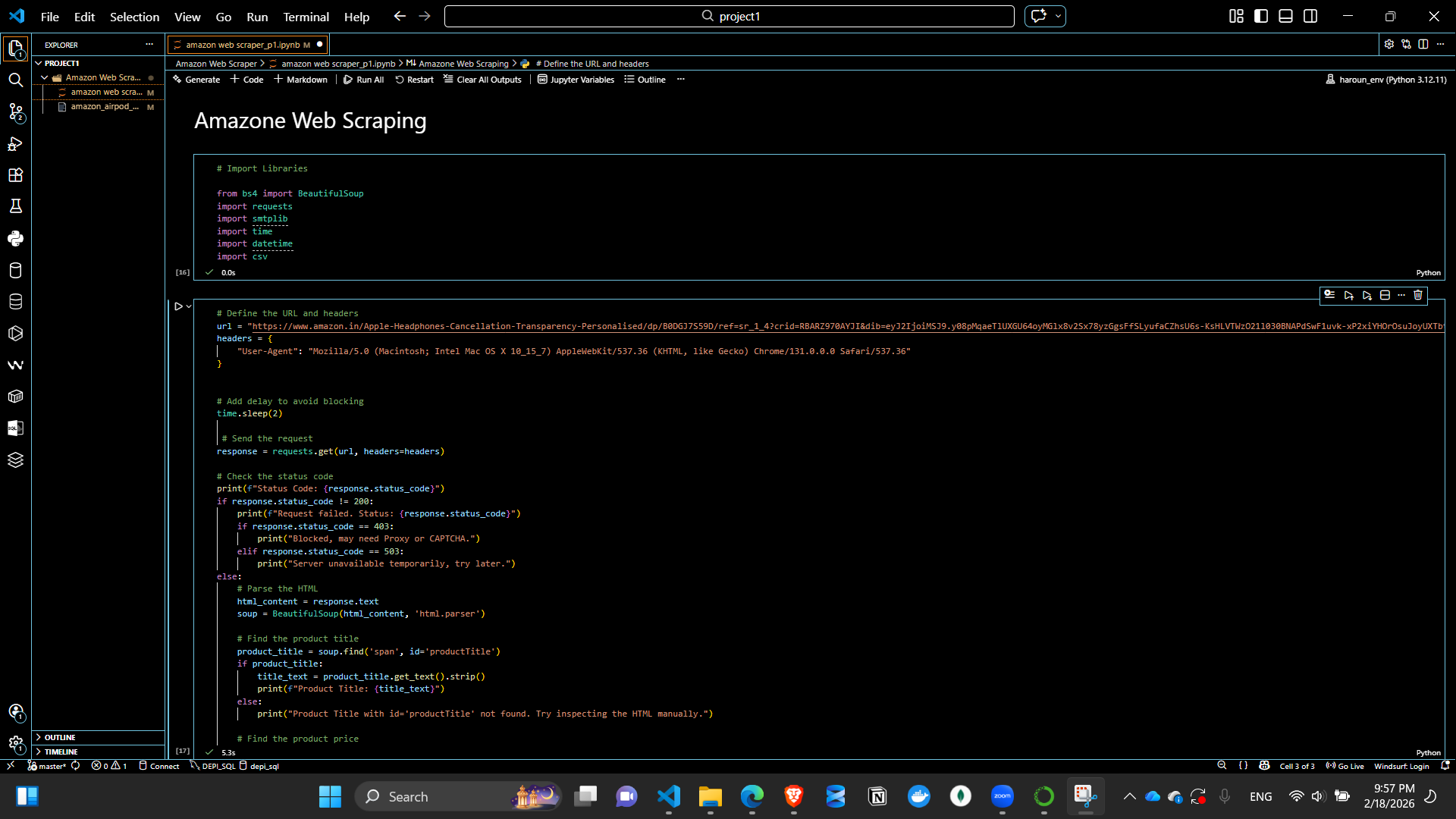
Scraper Code Preview1
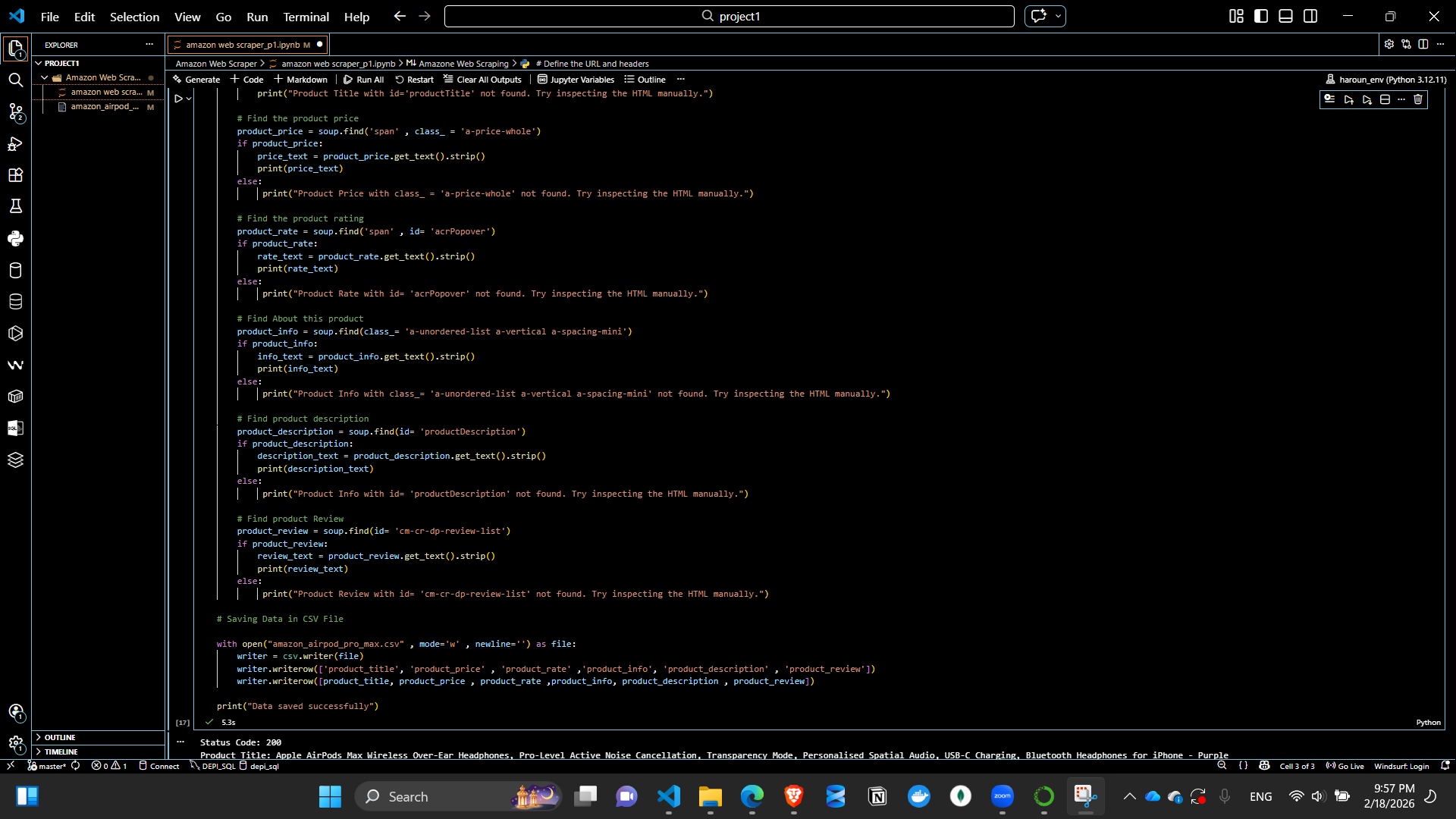
Scraper Code Preview2
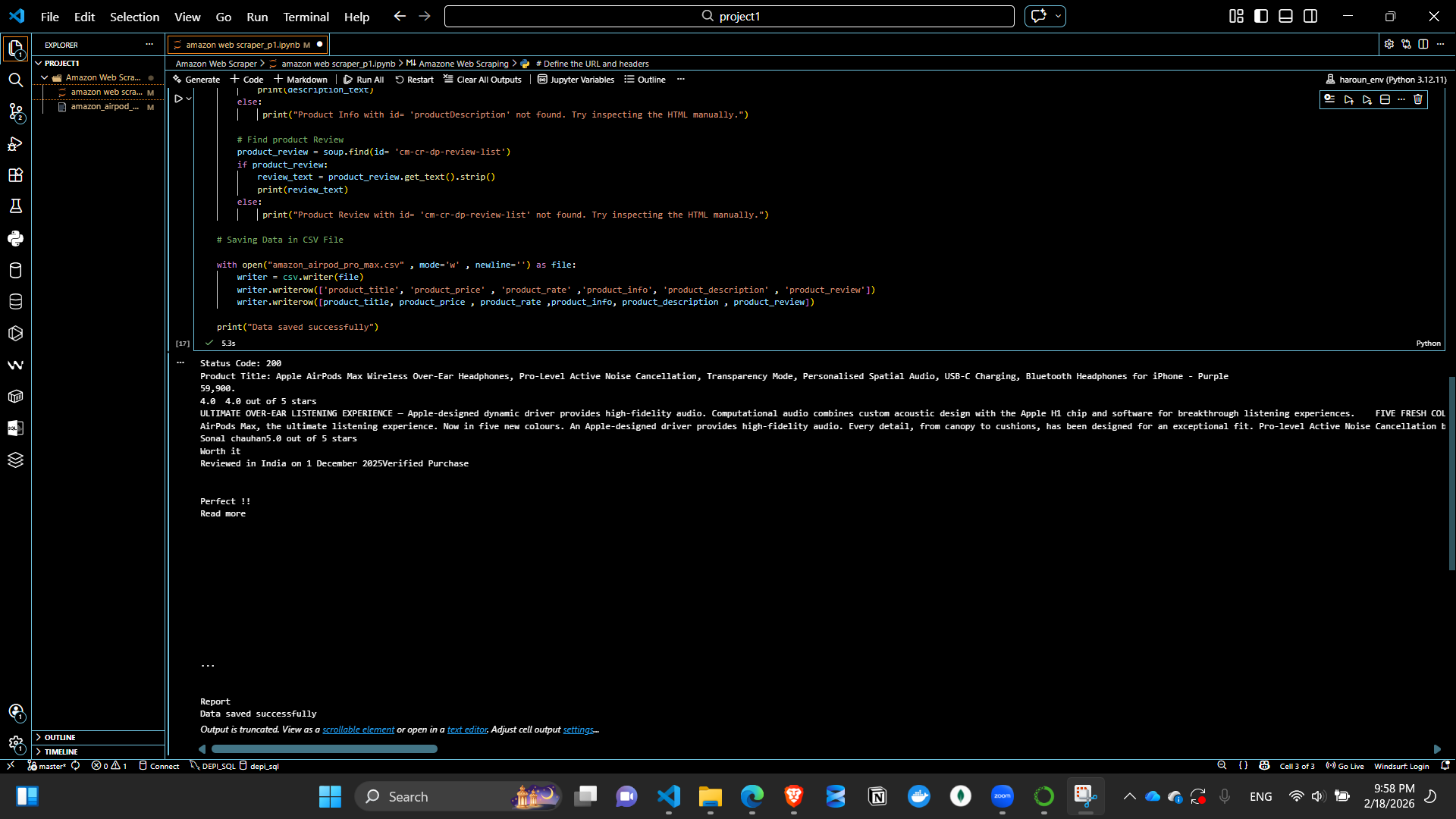
Scraper Code Preview3